Two Layer Neural Network
Original source code provided by Stanford University, see course notes for cs231n: Convolutional Neural Networks for Visual Recognition.
Implementing a Neural Network
In this exercise we will develop a neural network with fully-connected layers to perform classification, and test it out on the CIFAR-10 dataset.
# A bit of setup
import numpy as np
import matplotlib.pyplot as plt
from cs231n.classifiers.neural_net import TwoLayerNet
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# for auto-reloading external modules
# see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython
%load_ext autoreload
%autoreload 2
def rel_error(x, y):
""" returns relative error """
return np.max(np.abs(x - y) / (np.maximum(1e-8, np.abs(x) + np.abs(y))))
The autoreload extension is already loaded. To reload it, use:
%reload_ext autoreload
We will use the class TwoLayerNet in the file cs231n/classifiers/neural_net.py to represent instances of our network. The network parameters are stored in the instance variable self.params where keys are string parameter names and values are numpy arrays. Below, we initialize toy data and a toy model that we will use to develop your implementation.
# Create a small net and some toy data to check your implementations.
# Note that we set the random seed for repeatable experiments.
input_size = 4
hidden_size = 10
num_classes = 3
num_inputs = 5
def init_toy_model():
np.random.seed(0)
return TwoLayerNet(input_size, hidden_size, num_classes, std=1e-1)
def init_toy_data():
np.random.seed(1)
X = 10 * np.random.randn(num_inputs, input_size)
y = np.array([0, 1, 2, 2, 1])
return X, y
net = init_toy_model()
X, y = init_toy_data()
print(X)
[[ 16.24345364 -6.11756414 -5.28171752 -10.72968622]
[ 8.65407629 -23.01538697 17.44811764 -7.61206901]
[ 3.19039096 -2.49370375 14.62107937 -20.60140709]
[ -3.22417204 -3.84054355 11.33769442 -10.99891267]
[ -1.72428208 -8.77858418 0.42213747 5.82815214]]
print(y)
[0 1 2 2 1]
Forward pass: compute scores
Open the file cs231n/classifiers/neural_net.py and look at the method TwoLayerNet.loss. This function is very similar to the loss functions you have written for the SVM and Softmax exercises: It takes the data and weights and computes the class scores, the loss, and the gradients on the parameters.
Implement the first part of the forward pass which uses the weights and biases to compute the scores for all inputs.
scores = net.loss(X)
print('Your scores:')
print(scores)
print()
print('correct scores:')
correct_scores = np.asarray([
[-0.81233741, -1.27654624, -0.70335995],
[-0.17129677, -1.18803311, -0.47310444],
[-0.51590475, -1.01354314, -0.8504215 ],
[-0.15419291, -0.48629638, -0.52901952],
[-0.00618733, -0.12435261, -0.15226949]])
print(correct_scores)
print()
# The difference should be very small. We get < 1e-7
print('Difference between your scores and correct scores:')
print(np.sum(np.abs(scores - correct_scores)))
Your scores:
[[-0.81233741 -1.27654624 -0.70335995]
[-0.17129677 -1.18803311 -0.47310444]
[-0.51590475 -1.01354314 -0.8504215 ]
[-0.15419291 -0.48629638 -0.52901952]
[-0.00618733 -0.12435261 -0.15226949]]
correct scores:
[[-0.81233741 -1.27654624 -0.70335995]
[-0.17129677 -1.18803311 -0.47310444]
[-0.51590475 -1.01354314 -0.8504215 ]
[-0.15419291 -0.48629638 -0.52901952]
[-0.00618733 -0.12435261 -0.15226949]]
Difference between your scores and correct scores:
3.6802720496109664e-08
Forward pass: compute loss
In the same function, implement the second part that computes the data and regularization loss.
loss, _ = net.loss(X, y, reg=0.05)
correct_loss = 1.30378789133
# should be very small, we get < 1e-12
print('Difference between your loss and correct loss:')
print(np.sum(np.abs(loss - correct_loss)))
Difference between your loss and correct loss:
1.794120407794253e-13
Backward pass
Implement the rest of the function. This will compute the gradient of the loss with respect to the variables W1, b1, W2, and b2. Now that you (hopefully!) have a correctly implemented forward pass, you can debug your backward pass using a numeric gradient check:
from cs231n.gradient_check import eval_numerical_gradient
# Use numeric gradient checking to check your implementation of the backward pass.
# If your implementation is correct, the difference between the numeric and
# analytic gradients should be less than 1e-8 for each of W1, W2, b1, and b2.
loss, grads = net.loss(X, y, reg=0.05)
# these should all be less than 1e-8 or so
for param_name in grads:
f = lambda W: net.loss(X, y, reg=0.05)[0]
param_grad_num = eval_numerical_gradient(f, net.params[param_name], verbose=False)
print('%s max relative error: %e' % (param_name, rel_error(param_grad_num, grads[param_name])))
W2 max relative error: 3.440708e-09
b2 max relative error: 3.865028e-11
W1 max relative error: 3.669858e-09
b1 max relative error: 2.738422e-09
Train the network
To train the network we will use stochastic gradient descent (SGD), similar to the SVM and Softmax classifiers. Look at the function TwoLayerNet.train and fill in the missing sections to implement the training procedure. This should be very similar to the training procedure you used for the SVM and Softmax classifiers. You will also have to implement TwoLayerNet.predict, as the training process periodically performs prediction to keep track of accuracy over time while the network trains.
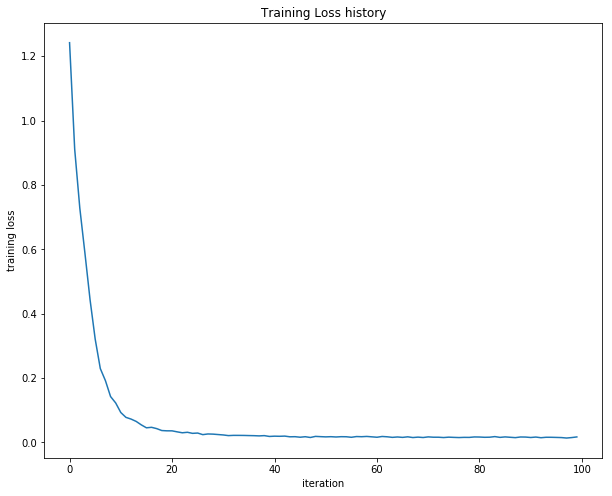
Once you have implemented the method, run the code below to train a two-layer network on toy data. You should achieve a training loss less than 0.02.
net = init_toy_model()
stats = net.train(X, y, X, y,
learning_rate=1e-1, reg=5e-6,
num_iters=100, verbose=True)
print('Final training loss: ', stats['loss_history'][-1])
# plot the loss history
plt.plot(stats['loss_history'])
plt.xlabel('iteration')
plt.ylabel('training loss')
plt.title('Training Loss history')
plt.show()
iteration 0 / 100: loss 1.241994
Final training loss: 0.017149607938732023
Load the data
Now that you have implemented a two-layer network that passes gradient checks and works on toy data, it’s time to load up our favorite CIFAR-10 data so we can use it to train a classifier on a real dataset.
from cs231n.data_utils import load_CIFAR10
def get_CIFAR10_data(num_training=49000, num_validation=1000, num_test=1000):
"""
Load the CIFAR-10 dataset from disk and perform preprocessing to prepare
it for the two-layer neural net classifier. These are the same steps as
we used for the SVM, but condensed to a single function.
"""
# Load the raw CIFAR-10 data
cifar10_dir = 'datasets/cifar-10-batches-py'
# Cleaning up variables to prevent loading data multiple times (which may cause memory issue)
try:
del X_train, y_train
del X_test, y_test
print('Clear previously loaded data.')
except:
pass
X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
# Visualize some examples from the dataset.
# We show a few examples of training images from each class.
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
num_classes = len(classes)
samples_per_class = 7
for y, cls in enumerate(classes):
idxs = np.flatnonzero(y_train == y)
idxs = np.random.choice(idxs, samples_per_class, replace=False)
for i, idx in enumerate(idxs):
plt_idx = i * num_classes + y + 1
plt.subplot(samples_per_class, num_classes, plt_idx)
plt.imshow(X_train[idx].astype('uint8'))
plt.axis('off')
if i == 0:
plt.title(cls)
plt.show()
# Subsample the data
mask = list(range(num_training, num_training + num_validation))
X_val = X_train[mask]
y_val = y_train[mask]
mask = list(range(num_training))
X_train = X_train[mask]
y_train = y_train[mask]
mask = list(range(num_test))
X_test = X_test[mask]
y_test = y_test[mask]
# Normalize the data: subtract the mean image
mean_image = np.mean(X_train, axis=0)
X_train -= mean_image
X_val -= mean_image
X_test -= mean_image
# Reshape data to rows
X_train = X_train.reshape(num_training, -1)
X_val = X_val.reshape(num_validation, -1)
X_test = X_test.reshape(num_test, -1)
return X_train, y_train, X_val, y_val, X_test, y_test
# Invoke the above function to get our data.
X_train, y_train, X_val, y_val, X_test, y_test = get_CIFAR10_data()
print('Train data shape: ', X_train.shape)
print('Train labels shape: ', y_train.shape)
print('Validation data shape: ', X_val.shape)
print('Validation labels shape: ', y_val.shape)
print('Test data shape: ', X_test.shape)
print('Test labels shape: ', y_test.shape)

Train data shape: (49000, 3072)
Train labels shape: (49000,)
Validation data shape: (1000, 3072)
Validation labels shape: (1000,)
Test data shape: (1000, 3072)
Test labels shape: (1000,)
Train a network
To train our network we will use SGD. In addition, we will adjust the learning rate with an exponential learning rate schedule as optimization proceeds; after each epoch, we will reduce the learning rate by multiplying it by a decay rate.
input_size = 32 * 32 * 3
hidden_size = 50
num_classes = 10
net = TwoLayerNet(input_size, hidden_size, num_classes)
print(net.params['W1'].shape)
# Train the network
stats = net.train(X_train, y_train, X_val, y_val,
num_iters=1000, batch_size=200,
learning_rate=1e-4, learning_rate_decay=0.95,
reg=0.25, verbose=True)
# Predict on the validation set
val_acc = (net.predict(X_val) == y_val).mean()
print('Validation accuracy: ', val_acc)
(3072, 50)
iteration 0 / 1000: loss 2.302976
iteration 100 / 1000: loss 2.302638
iteration 200 / 1000: loss 2.299256
iteration 300 / 1000: loss 2.270635
iteration 400 / 1000: loss 2.219117
iteration 500 / 1000: loss 2.141064
iteration 600 / 1000: loss 2.129066
iteration 700 / 1000: loss 2.047454
iteration 800 / 1000: loss 1.988162
iteration 900 / 1000: loss 1.967131
Validation accuracy: 0.282
Debug the training
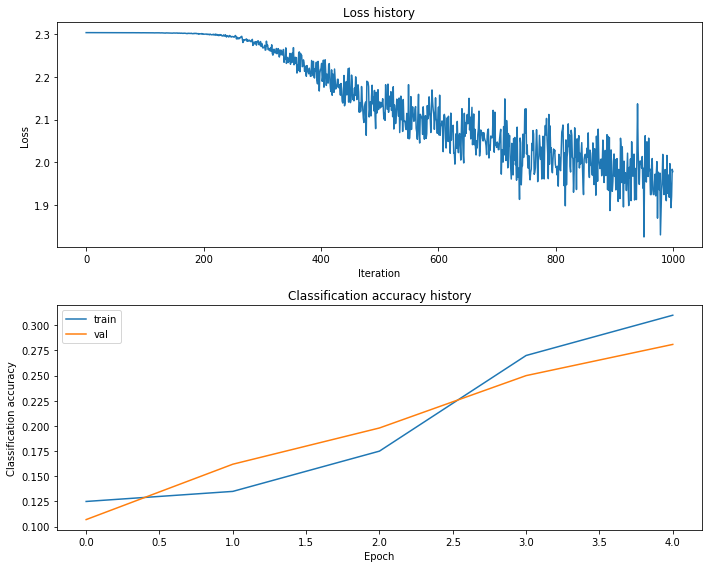
With the default parameters we provided above, you should get a validation accuracy of about 0.29 on the validation set. This isn’t very good.
One strategy for getting insight into what’s wrong is to plot the loss function and the accuracies on the training and validation sets during optimization.
Another strategy is to visualize the weights that were learned in the first layer of the network. In most neural networks trained on visual data, the first layer weights typically show some visible structure when visualized.
# Plot the loss function and train / validation accuracies
def plot_stats(stats):
plt.subplot(2, 1, 1)
plt.plot(stats['loss_history'])
plt.title('Loss history')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.subplot(2, 1, 2)
plt.plot(stats['train_acc_history'], label='train')
plt.plot(stats['val_acc_history'], label='val')
plt.title('Classification accuracy history')
plt.xlabel('Epoch')
plt.ylabel('Classification accuracy')
plt.legend()
plt.tight_layout()
plt.show()
plot_stats(stats)
print(stats['train_acc_history'])
print(stats['val_acc_history'])
[0.125, 0.135, 0.175, 0.27, 0.31]
[0.107, 0.162, 0.198, 0.25, 0.281]
from cs231n.vis_utils import visualize_grid
# Visualize the weights of the network
def show_net_weights(net):
W1 = net.params['W1']
W1 = W1.reshape(32, 32, 3, -1).transpose(3, 0, 1, 2)
plt.imshow(visualize_grid(W1, padding=3).astype('uint8'))
plt.gca().axis('off')
plt.show()
show_net_weights(net)

Tune your hyperparameters
What’s wrong?. Looking at the visualizations above, we see that the loss is decreasing more or less linearly, which seems to suggest that the learning rate may be too low. Moreover, there is no gap between the training and validation accuracy, suggesting that the model we used has low capacity, and that we should increase its size. On the other hand, with a very large model we would expect to see more overfitting, which would manifest itself as a very large gap between the training and validation accuracy.
Tuning. Tuning the hyperparameters and developing intuition for how they affect the final performance is a large part of using Neural Networks, so we want you to get a lot of practice. Below, you should experiment with different values of the various hyperparameters, including hidden layer size, learning rate, numer of training epochs, and regularization strength. You might also consider tuning the learning rate decay, but you should be able to get good performance using the default value.
Approximate results. You should be aim to achieve a classification accuracy of greater than 48% on the validation set. Our best network gets over 52% on the validation set.
Experiment: You goal in this exercise is to get as good of a result on CIFAR-10 as you can (52% could serve as a reference), with a fully-connected Neural Network. Feel free implement your own techniques (e.g. PCA to reduce dimensionality, or adding dropout, or adding features to the solver, etc.).
Explain your hyperparameter tuning process below.
$\color{blue}{\textit Your Answer:}$
best_net = None # store the best model into this
best_val = -1
best_stats = None
h = [150]
learning_rates = [1e-3]
regularization_strengths = [0.3]
results = {}
iters = 3000
for hidden_size in h:
for lr in learning_rates:
for rs in regularization_strengths:
net = TwoLayerNet(input_size, hidden_size, num_classes)
# Train the network
stats = net.train(X_train, y_train, X_val, y_val,
num_iters=iters, batch_size=200,
learning_rate=lr, learning_rate_decay=0.95,
reg=rs, verbose=False)
# Make predictions against training set
train_pred = net.predict(X_train)
# Get average training prediction accuracy
train_acc = np.mean(y_train == y_train_pred)
# Make predictions against validation set
val_pred = net.predict(X_val)
# Get average validation prediction accuracy
val_acc = np.mean(y_val == val_pred)
# Store results in dictionary using hyperparameters as key values
results[(hidden_size, lr, rs)] = (hidden_size, train_acc, val_acc)
# Update best validation accuracy if better results are obtained
if val_acc > best_val:
best_stats = stats
best_val = val_acc
best_net = net
# Print out results.
for h, lr, reg in sorted(results):
hidden_size, train_accuracy, val_accuracy = results[(h, lr, reg)]
print('h %s lr %e reg %e train accuracy: %f val accuracy: %f' % (
h, lr, reg, train_accuracy, val_accuracy))
print('best validation accuracy achieved during cross-validation: %f' % best_val)
plot_stats(best_stats)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
h 150 lr 1.000000e-03 reg 3.000000e-01 train accuracy: 0.229408 val accuracy: 0.520000
best validation accuracy achieved during cross-validation: 0.520000
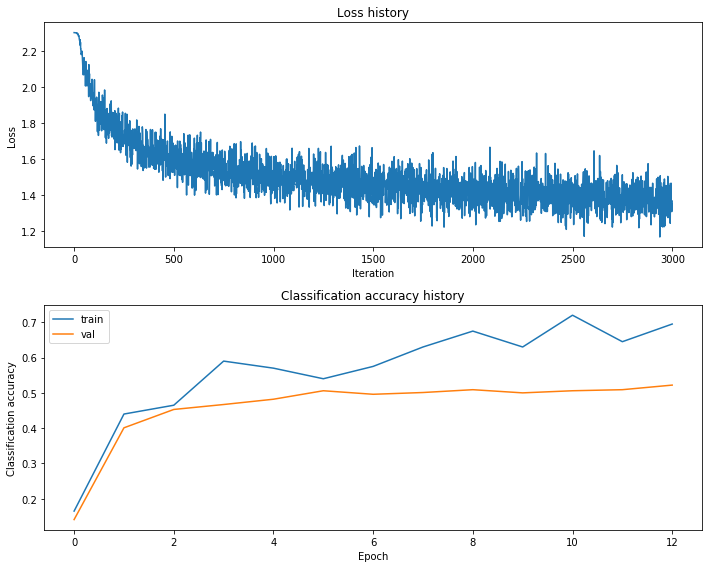
# visualize the weights of the best network
show_net_weights(best_net)

Run on the test set
When you are done experimenting, you should evaluate your final trained network on the test set; you should get above 48%.
test_acc = (best_net.predict(X_test) == y_test).mean()
print('Test accuracy: ', test_acc)
Test accuracy: 0.52
Inline Question
Now that you have trained a Neural Network classifier, you may find that your testing accuracy is much lower than the training accuracy. In what ways can we decrease this gap? Select all that apply.
- Train on a larger dataset.
- Add more hidden units.
- Increase the regularization strength.
- None of the above.
$\color{blue}{\textit Your Answer:}$
$\color{blue}{\textit Your Explanation:}$