Fully Connected Net
Original source code and content provided by Stanford University, see course notes for cs231n: Convolutional Neural Networks for Visual Recognition.
Fully-Connected Neural Nets
In the previous homework you implemented a fully-connected two-layer neural network on CIFAR-10. The implementation was simple but not very modular since the loss and gradient were computed in a single monolithic function. This is manageable for a simple two-layer network, but would become impractical as we move to bigger models. Ideally we want to build networks using a more modular design so that we can implement different layer types in isolation and then snap them together into models with different architectures.
In this exercise we will implement fully-connected networks using a more modular approach. For each layer we will implement a forward and a backward function. The forward function will receive inputs, weights, and other parameters and will return both an output and a cache object storing data needed for the backward pass, like this:
def layer_forward(x, w):
""" Receive inputs x and weights w """
# Do some computations ...
z = # ... some intermediate value
# Do some more computations ...
out = # the output
cache = (x, w, z, out) # Values we need to compute gradients
return out, cache
The backward pass will receive upstream derivatives and the cache object, and will return gradients with respect to the inputs and weights, like this:
def layer_backward(dout, cache):
"""
Receive dout (derivative of loss with respect to outputs) and cache,
and compute derivative with respect to inputs.
"""
# Unpack cache values
x, w, z, out = cache
# Use values in cache to compute derivatives
dx = # Derivative of loss with respect to x
dw = # Derivative of loss with respect to w
return dx, dw
After implementing a bunch of layers this way, we will be able to easily combine them to build classifiers with different architectures.
In addition to implementing fully-connected networks of arbitrary depth, we will also explore different update rules for optimization, and introduce Dropout as a regularizer and Batch/Layer Normalization as a tool to more efficiently optimize deep networks.
# As usual, a bit of setup
from __future__ import print_function
import time
import numpy as np
import matplotlib.pyplot as plt
from cs231n.classifiers.fc_net import *
from cs231n.layers import *
from cs231n.data_utils import get_CIFAR10_data
from cs231n.gradient_check import eval_numerical_gradient, eval_numerical_gradient_array
from cs231n.solver import Solver
%matplotlib inline
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
# for auto-reloading external modules
# see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython
%load_ext autoreload
%autoreload 2
def rel_error(x, y):
""" returns relative error """
if x is None or y is None:
print("None type object provided")
return None
else:
return np.max(np.abs(x - y) / (np.maximum(1e-8, np.abs(x) + np.abs(y))))
run the following from the cs231n directory and try again:
python setup.py build_ext --inplace
You may also need to restart your iPython kernel
# Load the (preprocessed) CIFAR10 data.
data = get_CIFAR10_data()
for k, v in list(data.items()):
print(('%s: ' % k, v.shape))
('X_train: ', (49000, 3, 32, 32))
('y_train: ', (49000,))
('X_val: ', (1000, 3, 32, 32))
('y_val: ', (1000,))
('X_test: ', (1000, 3, 32, 32))
('y_test: ', (1000,))
Affine layer: foward
Open the file cs231n/layers.py and implement the affine_forward function.
Once you are done you can test your implementaion by running the following:
# Test the affine_forward function
num_inputs = 2
input_shape = (4, 5, 6)
output_dim = 3
input_size = num_inputs * np.prod(input_shape)
weight_size = output_dim * np.prod(input_shape)
x = np.linspace(-0.1, 0.5, num=input_size).reshape(num_inputs, *input_shape)
w = np.linspace(-0.2, 0.3, num=weight_size).reshape(np.prod(input_shape), output_dim)
b = np.linspace(-0.3, 0.1, num=output_dim)
out, _ = affine_forward(x, w, b)
correct_out = np.array([[ 1.49834967, 1.70660132, 1.91485297],
[ 3.25553199, 3.5141327, 3.77273342]])
# Compare your output with ours. The error should be around e-9 or less.
print('Testing affine_forward function:')
print('difference: ', rel_error(out, correct_out))
Testing affine_forward function:
difference: 9.769847728806635e-10
Affine layer: backward
Now implement the affine_backward function and test your implementation using numeric gradient checking.
# Test the affine_backward function
np.random.seed(231)
x = np.random.randn(10, 2, 3)
w = np.random.randn(6, 5)
b = np.random.randn(5)
dout = np.random.randn(10, 5)
dx_num = eval_numerical_gradient_array(lambda x: affine_forward(x, w, b)[0], x, dout)
dw_num = eval_numerical_gradient_array(lambda w: affine_forward(x, w, b)[0], w, dout)
db_num = eval_numerical_gradient_array(lambda b: affine_forward(x, w, b)[0], b, dout)
_, cache = affine_forward(x, w, b)
dx, dw, db = affine_backward(dout, cache)
# The error should be around e-10 or less
print('Testing affine_backward function:')
print('dx error: ', rel_error(dx_num, dx))
print('dw error: ', rel_error(dw_num, dw))
print('db error: ', rel_error(db_num, db))
Testing affine_backward function:
dx error: 5.399100368651805e-11
dw error: 9.904211865398145e-11
db error: 2.4122867568119087e-11
ReLU activation: forward
Implement the forward pass for the ReLU activation function in the relu_forward function and test your implementation using the following:
# Test the relu_forward function
x = np.linspace(-0.5, 0.5, num=12).reshape(3, 4)
out, _ = relu_forward(x)
correct_out = np.array([[ 0., 0., 0., 0., ],
[ 0., 0., 0.04545455, 0.13636364,],
[ 0.22727273, 0.31818182, 0.40909091, 0.5, ]])
# Compare your output with ours. The error should be on the order of e-8
print('Testing relu_forward function:')
print('difference: ', rel_error(out, correct_out))
Testing relu_forward function:
difference: 4.999999798022158e-08
ReLU activation: backward
Now implement the backward pass for the ReLU activation function in the relu_backward function and test your implementation using numeric gradient checking:
np.random.seed(231)
x = np.random.randn(10, 10)
dout = np.random.randn(*x.shape)
dx_num = eval_numerical_gradient_array(lambda x: relu_forward(x)[0], x, dout)
_, cache = relu_forward(x)
dx = relu_backward(dout, cache)
# The error should be on the order of e-12
print('Testing relu_backward function:')
print('dx error: ', rel_error(dx_num, dx))
Testing relu_backward function:
dx error: 3.2756349136310288e-12
“Sandwich” layers
There are some common patterns of layers that are frequently used in neural nets. For example, affine layers are frequently followed by a ReLU nonlinearity. To make these common patterns easy, we define several convenience layers in the file cs231n/layer_utils.py.
For now take a look at the affine_relu_forward and affine_relu_backward functions, and run the following to numerically gradient check the backward pass:
from cs231n.layer_utils import affine_relu_forward, affine_relu_backward
np.random.seed(231)
x = np.random.randn(2, 3, 4)
w = np.random.randn(12, 10)
b = np.random.randn(10)
dout = np.random.randn(2, 10)
out, cache = affine_relu_forward(x, w, b)
dx, dw, db = affine_relu_backward(dout, cache)
dx_num = eval_numerical_gradient_array(lambda x: affine_relu_forward(x, w, b)[0], x, dout)
dw_num = eval_numerical_gradient_array(lambda w: affine_relu_forward(x, w, b)[0], w, dout)
db_num = eval_numerical_gradient_array(lambda b: affine_relu_forward(x, w, b)[0], b, dout)
# Relative error should be around e-10 or less
print('Testing affine_relu_forward and affine_relu_backward:')
print('dx error: ', rel_error(dx_num, dx))
print('dw error: ', rel_error(dw_num, dw))
print('db error: ', rel_error(db_num, db))
Testing affine_relu_forward and affine_relu_backward:
dx error: 6.750562121603446e-11
dw error: 8.162015570444288e-11
db error: 7.826724021458994e-12
Loss layers: Softmax and SVM
You implemented these loss functions in the last assignment, so we’ll give them to you for free here. You should still make sure you understand how they work by looking at the implementations in cs231n/layers.py.
You can make sure that the implementations are correct by running the following:
np.random.seed(231)
num_classes, num_inputs = 10, 50
x = 0.001 * np.random.randn(num_inputs, num_classes)
y = np.random.randint(num_classes, size=num_inputs)
dx_num = eval_numerical_gradient(lambda x: svm_loss(x, y)[0], x, verbose=False)
loss, dx = svm_loss(x, y)
# Test svm_loss function. Loss should be around 9 and dx error should be around the order of e-9
print('Testing svm_loss:')
print('loss: ', loss)
print('dx error: ', rel_error(dx_num, dx))
dx_num = eval_numerical_gradient(lambda x: softmax_loss(x, y)[0], x, verbose=False)
loss, dx = softmax_loss(x, y)
# Test softmax_loss function. Loss should be close to 2.3 and dx error should be around e-8
print('\nTesting softmax_loss:')
print('loss: ', loss)
print('dx error: ', rel_error(dx_num, dx))
Testing svm_loss:
loss: 8.999602749096233
dx error: 1.4021566006651672e-09
Testing softmax_loss:
loss: 2.302545844500738
dx error: 9.384673161989355e-09
Two-layer network
In the previous assignment you implemented a two-layer neural network in a single monolithic class. Now that you have implemented modular versions of the necessary layers, you will reimplement the two layer network using these modular implementations.
Open the file cs231n/classifiers/fc_net.py and complete the implementation of the TwoLayerNet class. This class will serve as a model for the other networks you will implement in this assignment, so read through it to make sure you understand the API. You can run the cell below to test your implementation.
np.random.seed(231)
N, D, H, C = 3, 5, 50, 7
X = np.random.randn(N, D)
y = np.random.randint(C, size=N)
std = 1e-3
model = TwoLayerNet(input_dim=D, hidden_dim=H, num_classes=C, weight_scale=std)
print('Testing initialization ... ')
W1_std = abs(model.params['W1'].std() - std)
b1 = model.params['b1']
W2_std = abs(model.params['W2'].std() - std)
b2 = model.params['b2']
assert W1_std < std / 10, 'First layer weights do not seem right'
assert np.all(b1 == 0), 'First layer biases do not seem right'
assert W2_std < std / 10, 'Second layer weights do not seem right'
assert np.all(b2 == 0), 'Second layer biases do not seem right'
print('Testing test-time forward pass ... ')
model.params['W1'] = np.linspace(-0.7, 0.3, num=D*H).reshape(D, H)
model.params['b1'] = np.linspace(-0.1, 0.9, num=H)
model.params['W2'] = np.linspace(-0.3, 0.4, num=H*C).reshape(H, C)
model.params['b2'] = np.linspace(-0.9, 0.1, num=C)
X = np.linspace(-5.5, 4.5, num=N*D).reshape(D, N).T
scores = model.loss(X)
correct_scores = np.asarray(
[[11.53165108, 12.2917344, 13.05181771, 13.81190102, 14.57198434, 15.33206765, 16.09215096],
[12.05769098, 12.74614105, 13.43459113, 14.1230412, 14.81149128, 15.49994135, 16.18839143],
[12.58373087, 13.20054771, 13.81736455, 14.43418138, 15.05099822, 15.66781506, 16.2846319 ]])
scores_diff = np.abs(scores - correct_scores).sum()
assert scores_diff < 1e-6, 'Problem with test-time forward pass'
print('Testing training loss (no regularization)')
y = np.asarray([0, 5, 1])
loss, grads = model.loss(X, y)
correct_loss = 3.4702243556
assert abs(loss - correct_loss) < 1e-10, 'Problem with training-time loss'
model.reg = 1.0
loss, grads = model.loss(X, y)
correct_loss = 26.5948426952
assert abs(loss - correct_loss) < 1e-10, 'Problem with regularization loss'
# Errors should be around e-7 or less
for reg in [0.0, 0.3, 0.7]:
print('Running numeric gradient check with reg = ', reg)
model.reg = reg
loss, grads = model.loss(X, y)
for name in sorted(grads):
f = lambda _: model.loss(X, y)[0]
grad_num = eval_numerical_gradient(f, model.params[name], verbose=False)
print('%s relative error: %.2e' % (name, rel_error(grad_num, grads[name])))
Testing initialization ...
Testing test-time forward pass ...
Testing training loss (no regularization)
Running numeric gradient check with reg = 0.0
W1 relative error: 1.52e-08
W2 relative error: 3.48e-10
b1 relative error: 6.55e-09
b2 relative error: 4.33e-10
Running numeric gradient check with reg = 0.3
W1 relative error: 8.67e-08
W2 relative error: 7.20e-10
b1 relative error: 8.37e-09
b2 relative error: 7.76e-10
Running numeric gradient check with reg = 0.7
W1 relative error: 8.18e-07
W2 relative error: 7.98e-08
b1 relative error: 1.09e-09
b2 relative error: 7.76e-10
Solver
In the previous assignment, the logic for training models was coupled to the models themselves. Following a more modular design, for this assignment we have split the logic for training models into a separate class.
Open the file cs231n/solver.py and read through it to familiarize yourself with the API. After doing so, use a Solver instance to train a TwoLayerNet that achieves at least 50% accuracy on the validation set.
solver = None
##############################################################################
# TODO: Use a Solver instance to train a TwoLayerNet that achieves at least #
# 50% accuracy on the validation set. #
##############################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
def init_toy_data():
N, D, H, C = 5, 4, 10, 3
np.random.seed(1)
X = 10 * np.random.randn(N, D)
y = np.array([0, 1, 2, 2, 1])
data = {}
data['X_train'] = X
data['y_train'] = y
data['X_val'] = X
data['y_val'] = y
return data, N, D, H, C
def init_cifar():
D, H, C = 3072, 150, 10
N = 10000
data = get_CIFAR10_data()
data['X_train'] = np.reshape(data['X_train'], (data['X_train'].shape[0], -1))[0:N]
data['y_train'] = data['y_train'][0:N]
data['X_val'] = np.reshape(data['X_val'], (data['X_val'].shape[0], -1))
data['X_test'] = np.reshape(data['X_test'], (data['X_test'].shape[0], -1))
for k, v in list(data.items()):
print(('%s: ' % k, v.shape))
return data, N, D, H, C
def init_random_data():
np.random.seed(0)
N, D, H, C = 500, 1000, 50, 10
data = {}
data['X_train'] = np.random.randn(N, D)
data['y_train'] = np.random.randint(C, size=N)
data['X_val'] = data['X_train'][-100:]
data['y_val'] = data['y_train'][-100:]
return data, N, D, H, C
data, N, D, H, C = init_cifar()
batch_s = int(max(N/50, 1))
std=1e-3
best_val = -1
best_tr = -1
best_solver = None
for lr in [1e-3]:
for r in [0.1]:
model = TwoLayerNet(input_dim=D, hidden_dim=H, num_classes=C, weight_scale=std, reg=r)
solver = Solver(model, data, update_rule='sgd',
optim_config={
'learning_rate': lr
}, lr_decay=0.95, num_epochs=20, batch_size=batch_s, print_every=100,
verbose=True, num_train_samples=None, num_val_samples=None)
solver.train()
val_acc = np.max(solver.val_acc_history)
tr_acc = np.max(solver.train_acc_history)
if (val_acc > best_val) or (not (val_acc < best_val) and tr_acc > best_tr):
best_solver = solver
best_val = val_acc
best_tr = tr_acc
params = (lr, r)
solver = best_solver
print("Best Training Accuracy: %f" % best_tr)
print("Best Validation Accuracy: %f" % best_val)
print("Best Validation Params: lr: %e, reg: %f" % (params[0], params[1]))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
##############################################################################
# END OF YOUR CODE #
##############################################################################
('X_train: ', (10000, 3072))
('y_train: ', (10000,))
('X_val: ', (1000, 3072))
('y_val: ', (1000,))
('X_test: ', (1000, 3072))
('y_test: ', (1000,))
(Iteration 1 / 1000) loss: 2.325526
(Epoch 0 / 20) train acc: 0.156200; val_acc: 0.148000
(Epoch 1 / 20) train acc: 0.328700; val_acc: 0.329000
(Epoch 2 / 20) train acc: 0.383600; val_acc: 0.377000
(Iteration 101 / 1000) loss: 1.722768
(Epoch 3 / 20) train acc: 0.424500; val_acc: 0.393000
(Epoch 4 / 20) train acc: 0.445500; val_acc: 0.419000
(Iteration 201 / 1000) loss: 1.544414
(Epoch 5 / 20) train acc: 0.462100; val_acc: 0.419000
(Epoch 6 / 20) train acc: 0.489400; val_acc: 0.421000
(Iteration 301 / 1000) loss: 1.478097
(Epoch 7 / 20) train acc: 0.500300; val_acc: 0.429000
(Epoch 8 / 20) train acc: 0.519500; val_acc: 0.430000
(Iteration 401 / 1000) loss: 1.477998
(Epoch 9 / 20) train acc: 0.536400; val_acc: 0.418000
(Epoch 10 / 20) train acc: 0.535100; val_acc: 0.422000
(Iteration 501 / 1000) loss: 1.442219
(Epoch 11 / 20) train acc: 0.554100; val_acc: 0.438000
(Epoch 12 / 20) train acc: 0.572400; val_acc: 0.436000
(Iteration 601 / 1000) loss: 1.323054
(Epoch 13 / 20) train acc: 0.580600; val_acc: 0.423000
(Epoch 14 / 20) train acc: 0.594200; val_acc: 0.440000
(Iteration 701 / 1000) loss: 1.173297
(Epoch 15 / 20) train acc: 0.603800; val_acc: 0.455000
(Epoch 16 / 20) train acc: 0.619300; val_acc: 0.452000
(Iteration 801 / 1000) loss: 1.117840
(Epoch 17 / 20) train acc: 0.631600; val_acc: 0.444000
(Epoch 18 / 20) train acc: 0.641300; val_acc: 0.448000
(Iteration 901 / 1000) loss: 1.159270
(Epoch 19 / 20) train acc: 0.648900; val_acc: 0.453000
(Epoch 20 / 20) train acc: 0.660900; val_acc: 0.463000
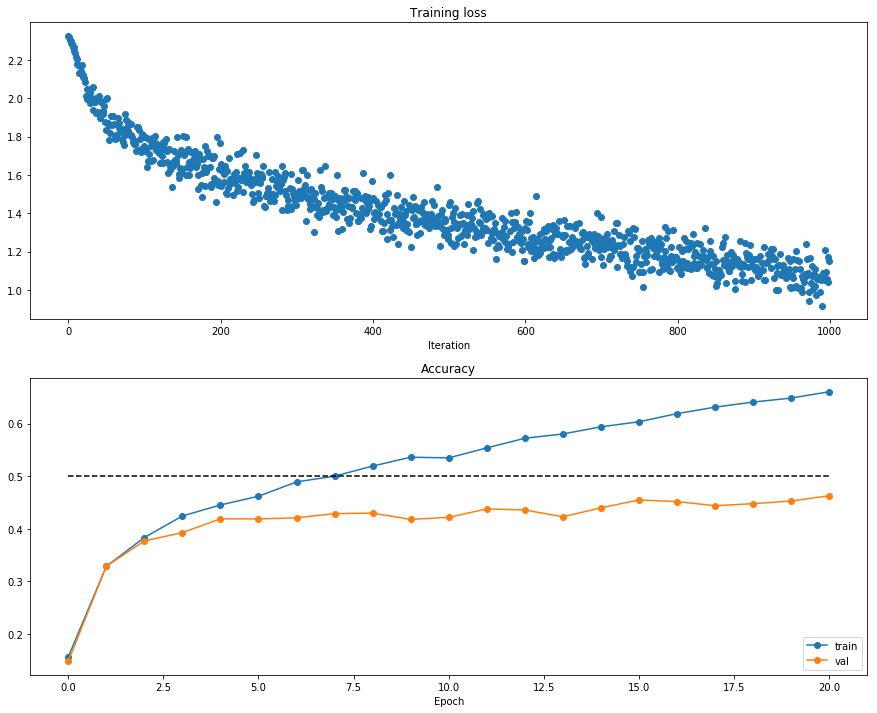
Best Training Accuracy: 0.660900
Best Validation Accuracy: 0.463000
Best Validation Params: lr: 1.000000e-03, reg: 0.100000
# Run this cell to visualize training loss and train / val accuracy
plt.subplot(2, 1, 1)
plt.title('Training loss')
plt.plot(solver.loss_history, 'o')
plt.xlabel('Iteration')
plt.subplot(2, 1, 2)
plt.title('Accuracy')
plt.plot(solver.train_acc_history, '-o', label='train')
plt.plot(solver.val_acc_history, '-o', label='val')
plt.plot([0.5] * len(solver.val_acc_history), 'k--')
plt.xlabel('Epoch')
plt.legend(loc='lower right')
plt.gcf().set_size_inches(15, 12)
plt.show()
Multilayer network
Next you will implement a fully-connected network with an arbitrary number of hidden layers.
Read through the FullyConnectedNet class in the file cs231n/classifiers/fc_net.py.
Implement the initialization, the forward pass, and the backward pass. For the moment don’t worry about implementing dropout or batch/layer normalization; we will add those features soon.
Initial loss and gradient check
As a sanity check, run the following to check the initial loss and to gradient check the network both with and without regularization. Do the initial losses seem reasonable?
For gradient checking, you should expect to see errors around 1e-7 or less.
np.random.seed(231)
N, D, C = 2, 15, 10
H = [20, 30]
X = np.random.randn(N, D)
y = np.random.randint(C, size=(N,))
reg = 0
model = FullyConnectedNet(H, input_dim=D, num_classes=C,
reg=reg, weight_scale=5e-2, dtype=np.float64)
loss, grads = model.loss(X, y)
print('Initial loss: ', loss)
Initial loss: 2.3004790897684924
np.random.seed(231)
N, D, C = 2, 15, 10
X = np.random.randn(N, D)
y = np.random.randint(C, size=(N,))
for reg in [0, 3.14]:
print('Running check with reg = ', reg)
model = FullyConnectedNet(H, input_dim=D, num_classes=C,
reg=reg, weight_scale=5e-2, dtype=np.float64)
loss, grads = model.loss(X, y)
print('Initial loss: ', loss)
# Most of the errors should be on the order of e-7 or smaller.
# NOTE: It is fine however to see an error for W2 on the order of e-5
# for the check when reg = 0.0
for name in sorted(grads):
f = lambda _: model.loss(X, y)[0]
grad_num = eval_numerical_gradient(f, model.params[name], verbose=False, h=1e-5)
print('%s relative error: %.2e' % (name, rel_error(grad_num, grads[name])))
Running check with reg = 0
Initial loss: 2.3004790897684924
W1 relative error: 1.48e-07
W2 relative error: 2.21e-05
W3 relative error: 3.53e-07
b1 relative error: 5.38e-09
b2 relative error: 2.09e-09
b3 relative error: 5.80e-11
Running check with reg = 3.14
Initial loss: 7.052114776533016
W1 relative error: 1.14e-08
W2 relative error: 6.87e-08
W3 relative error: 3.48e-08
b1 relative error: 1.48e-08
b2 relative error: 1.72e-09
b3 relative error: 1.80e-10
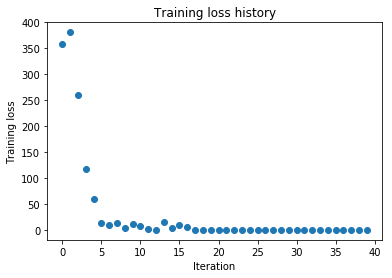
As another sanity check, make sure you can overfit a small dataset of 50 images. First we will try a three-layer network with 100 units in each hidden layer. In the following cell, tweak the learning rate and weight initialization scale to overfit and achieve 100% training accuracy within 20 epochs.
# TODO: Use a three-layer Net to overfit 50 training examples by
# tweaking just the learning rate and initialization scale.
num_train = 50
small_data = {
'X_train': data['X_train'][:num_train],
'y_train': data['y_train'][:num_train],
'X_val': data['X_val'],
'y_val': data['y_val'],
}
weight_scale = 1e-1 # Experiment with this!
learning_rate = 1e-3 # Experiment with this!
model = FullyConnectedNet([100, 100],
weight_scale=weight_scale, dtype=np.float64)
solver = Solver(model, small_data,
print_every=10, num_epochs=20, batch_size=25,
update_rule='sgd',
optim_config={
'learning_rate': learning_rate,
}
)
solver.train()
plt.plot(solver.loss_history, 'o')
plt.title('Training loss history')
plt.xlabel('Iteration')
plt.ylabel('Training loss')
plt.show()
(Iteration 1 / 40) loss: 357.428290
(Epoch 0 / 20) train acc: 0.220000; val_acc: 0.111000
(Epoch 1 / 20) train acc: 0.380000; val_acc: 0.141000
(Epoch 2 / 20) train acc: 0.520000; val_acc: 0.138000
(Epoch 3 / 20) train acc: 0.740000; val_acc: 0.130000
(Epoch 4 / 20) train acc: 0.820000; val_acc: 0.153000
(Epoch 5 / 20) train acc: 0.860000; val_acc: 0.175000
(Iteration 11 / 40) loss: 6.726589
(Epoch 6 / 20) train acc: 0.940000; val_acc: 0.163000
(Epoch 7 / 20) train acc: 0.960000; val_acc: 0.166000
(Epoch 8 / 20) train acc: 0.960000; val_acc: 0.164000
(Epoch 9 / 20) train acc: 0.980000; val_acc: 0.162000
(Epoch 10 / 20) train acc: 0.980000; val_acc: 0.162000
(Iteration 21 / 40) loss: 0.800243
(Epoch 11 / 20) train acc: 1.000000; val_acc: 0.158000
(Epoch 12 / 20) train acc: 1.000000; val_acc: 0.158000
(Epoch 13 / 20) train acc: 1.000000; val_acc: 0.158000
(Epoch 14 / 20) train acc: 1.000000; val_acc: 0.158000
(Epoch 15 / 20) train acc: 1.000000; val_acc: 0.158000
(Iteration 31 / 40) loss: 0.000000
(Epoch 16 / 20) train acc: 1.000000; val_acc: 0.158000
(Epoch 17 / 20) train acc: 1.000000; val_acc: 0.158000
(Epoch 18 / 20) train acc: 1.000000; val_acc: 0.158000
(Epoch 19 / 20) train acc: 1.000000; val_acc: 0.158000
(Epoch 20 / 20) train acc: 1.000000; val_acc: 0.158000
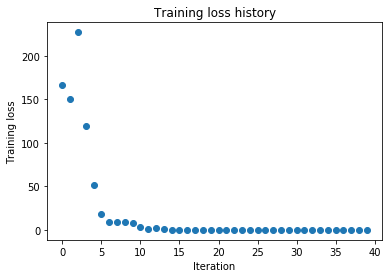
Now try to use a five-layer network with 100 units on each layer to overfit 50 training examples. Again, you will have to adjust the learning rate and weight initialization scale, but you should be able to achieve 100% training accuracy within 20 epochs.
# TODO: Use a five-layer Net to overfit 50 training examples by
# tweaking just the learning rate and initialization scale.
num_train = 50
small_data = {
'X_train': data['X_train'][:num_train],
'y_train': data['y_train'][:num_train],
'X_val': data['X_val'],
'y_val': data['y_val'],
}
learning_rate = 2e-3 # Experiment with this!
weight_scale = 1e-1 # Experiment with this!
model = FullyConnectedNet([100, 100, 100, 100],
weight_scale=weight_scale, dtype=np.float64)
solver = Solver(model, small_data,
print_every=10, num_epochs=20, batch_size=25,
update_rule='sgd',
optim_config={
'learning_rate': learning_rate,
}
)
solver.train()
plt.plot(solver.loss_history, 'o')
plt.title('Training loss history')
plt.xlabel('Iteration')
plt.ylabel('Training loss')
plt.show()
(Iteration 1 / 40) loss: 166.501707
(Epoch 0 / 20) train acc: 0.100000; val_acc: 0.107000
(Epoch 1 / 20) train acc: 0.320000; val_acc: 0.101000
(Epoch 2 / 20) train acc: 0.160000; val_acc: 0.122000
(Epoch 3 / 20) train acc: 0.380000; val_acc: 0.106000
(Epoch 4 / 20) train acc: 0.520000; val_acc: 0.111000
(Epoch 5 / 20) train acc: 0.760000; val_acc: 0.113000
(Iteration 11 / 40) loss: 3.343141
(Epoch 6 / 20) train acc: 0.840000; val_acc: 0.122000
(Epoch 7 / 20) train acc: 0.920000; val_acc: 0.113000
(Epoch 8 / 20) train acc: 0.940000; val_acc: 0.125000
(Epoch 9 / 20) train acc: 0.960000; val_acc: 0.125000
(Epoch 10 / 20) train acc: 0.980000; val_acc: 0.121000
(Iteration 21 / 40) loss: 0.039138
(Epoch 11 / 20) train acc: 0.980000; val_acc: 0.123000
(Epoch 12 / 20) train acc: 1.000000; val_acc: 0.121000
(Epoch 13 / 20) train acc: 1.000000; val_acc: 0.121000
(Epoch 14 / 20) train acc: 1.000000; val_acc: 0.121000
(Epoch 15 / 20) train acc: 1.000000; val_acc: 0.121000
(Iteration 31 / 40) loss: 0.000644
(Epoch 16 / 20) train acc: 1.000000; val_acc: 0.121000
(Epoch 17 / 20) train acc: 1.000000; val_acc: 0.121000
(Epoch 18 / 20) train acc: 1.000000; val_acc: 0.121000
(Epoch 19 / 20) train acc: 1.000000; val_acc: 0.121000
(Epoch 20 / 20) train acc: 1.000000; val_acc: 0.121000
Update rules
So far we have used vanilla stochastic gradient descent (SGD) as our update rule. More sophisticated update rules can make it easier to train deep networks. We will implement a few of the most commonly used update rules and compare them to vanilla SGD.
SGD+Momentum
Stochastic gradient descent with momentum is a widely used update rule that tends to make deep networks converge faster than vanilla stochastic gradient descent. See the Momentum Update section at http://cs231n.github.io/neural-networks-3/#sgd for more information.
Open the file cs231n/optim.py and read the documentation at the top of the file to make sure you understand the API. Implement the SGD+momentum update rule in the function sgd_momentum and run the following to check your implementation. You should see errors less than e-8.
from cs231n.optim import sgd_momentum
N, D = 4, 5
w = np.linspace(-0.4, 0.6, num=N*D).reshape(N, D)
dw = np.linspace(-0.6, 0.4, num=N*D).reshape(N, D)
v = np.linspace(0.6, 0.9, num=N*D).reshape(N, D)
config = {'learning_rate': 1e-3, 'velocity': v}
next_w, _ = sgd_momentum(w, dw, config=config)
expected_next_w = np.asarray([
[ 0.1406, 0.20738947, 0.27417895, 0.34096842, 0.40775789],
[ 0.47454737, 0.54133684, 0.60812632, 0.67491579, 0.74170526],
[ 0.80849474, 0.87528421, 0.94207368, 1.00886316, 1.07565263],
[ 1.14244211, 1.20923158, 1.27602105, 1.34281053, 1.4096 ]])
expected_velocity = np.asarray([
[ 0.5406, 0.55475789, 0.56891579, 0.58307368, 0.59723158],
[ 0.61138947, 0.62554737, 0.63970526, 0.65386316, 0.66802105],
[ 0.68217895, 0.69633684, 0.71049474, 0.72465263, 0.73881053],
[ 0.75296842, 0.76712632, 0.78128421, 0.79544211, 0.8096 ]])
# Should see relative errors around e-8 or less
print('next_w error: ', rel_error(next_w, expected_next_w))
print('velocity error: ', rel_error(expected_velocity, config['velocity']))
next_w error: 8.882347033505819e-09
velocity error: 4.269287743278663e-09
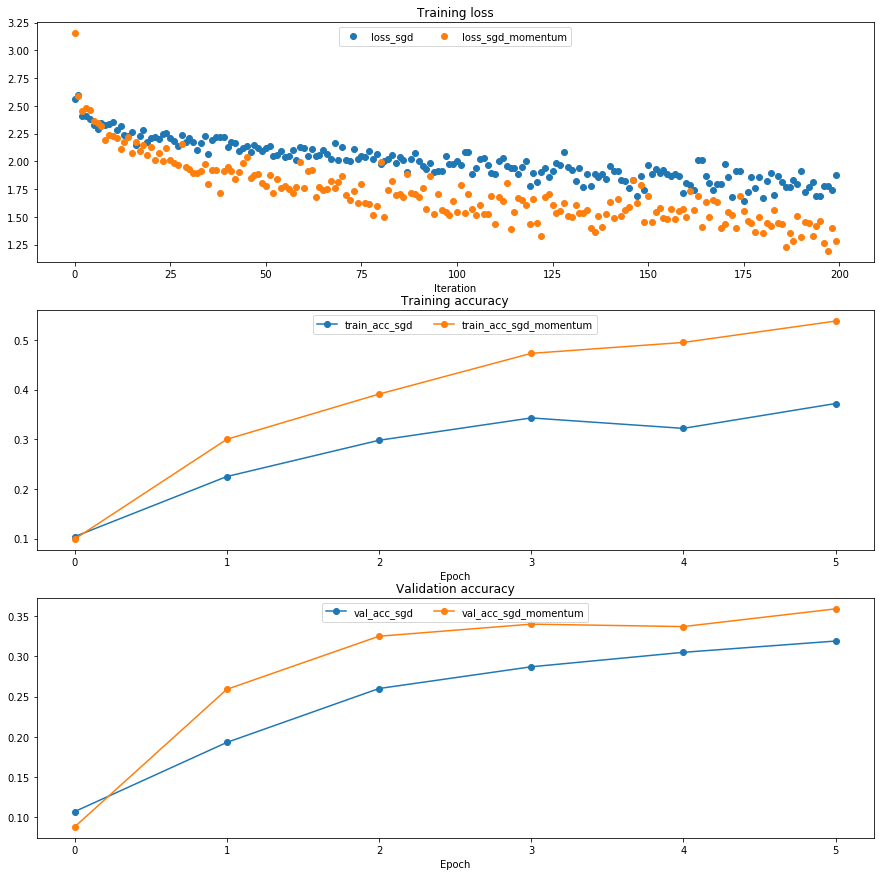
Once you have done so, run the following to train a six-layer network with both SGD and SGD+momentum. You should see the SGD+momentum update rule converge faster.
num_train = 4000
small_data = {
'X_train': data['X_train'][:num_train],
'y_train': data['y_train'][:num_train],
'X_val': data['X_val'],
'y_val': data['y_val'],
}
solvers = {}
for update_rule in ['sgd', 'sgd_momentum']:
print('running with ', update_rule)
model = FullyConnectedNet([100, 100, 100, 100, 100], weight_scale=5e-2)
solver = Solver(model, small_data,
num_epochs=5, batch_size=100,
update_rule=update_rule,
optim_config={
'learning_rate': 5e-3,
},
verbose=True)
solvers[update_rule] = solver
solver.train()
print()
plt.subplot(3, 1, 1)
plt.title('Training loss')
plt.xlabel('Iteration')
plt.subplot(3, 1, 2)
plt.title('Training accuracy')
plt.xlabel('Epoch')
plt.subplot(3, 1, 3)
plt.title('Validation accuracy')
plt.xlabel('Epoch')
for update_rule, solver in solvers.items():
plt.subplot(3, 1, 1)
plt.plot(solver.loss_history, 'o', label="loss_%s" % update_rule)
plt.subplot(3, 1, 2)
plt.plot(solver.train_acc_history, '-o', label="train_acc_%s" % update_rule)
plt.subplot(3, 1, 3)
plt.plot(solver.val_acc_history, '-o', label="val_acc_%s" % update_rule)
for i in [1, 2, 3]:
plt.subplot(3, 1, i)
plt.legend(loc='upper center', ncol=4)
plt.gcf().set_size_inches(15, 15)
plt.show()
running with sgd
(Iteration 1 / 200) loss: 2.559978
(Epoch 0 / 5) train acc: 0.104000; val_acc: 0.107000
(Iteration 11 / 200) loss: 2.356069
(Iteration 21 / 200) loss: 2.214091
(Iteration 31 / 200) loss: 2.205928
(Epoch 1 / 5) train acc: 0.225000; val_acc: 0.193000
(Iteration 41 / 200) loss: 2.132095
(Iteration 51 / 200) loss: 2.118950
(Iteration 61 / 200) loss: 2.116443
(Iteration 71 / 200) loss: 2.132549
(Epoch 2 / 5) train acc: 0.298000; val_acc: 0.260000
(Iteration 81 / 200) loss: 1.977227
(Iteration 91 / 200) loss: 2.007528
(Iteration 101 / 200) loss: 2.004762
(Iteration 111 / 200) loss: 1.885342
(Epoch 3 / 5) train acc: 0.343000; val_acc: 0.287000
(Iteration 121 / 200) loss: 1.891516
(Iteration 131 / 200) loss: 1.923677
(Iteration 141 / 200) loss: 1.957744
(Iteration 151 / 200) loss: 1.966736
(Epoch 4 / 5) train acc: 0.322000; val_acc: 0.305000
(Iteration 161 / 200) loss: 1.801483
(Iteration 171 / 200) loss: 1.973779
(Iteration 181 / 200) loss: 1.666572
(Iteration 191 / 200) loss: 1.909494
(Epoch 5 / 5) train acc: 0.372000; val_acc: 0.319000
running with sgd_momentum
(Iteration 1 / 200) loss: 3.153778
(Epoch 0 / 5) train acc: 0.099000; val_acc: 0.088000
(Iteration 11 / 200) loss: 2.227203
(Iteration 21 / 200) loss: 2.125322
(Iteration 31 / 200) loss: 1.933623
(Epoch 1 / 5) train acc: 0.300000; val_acc: 0.259000
(Iteration 41 / 200) loss: 1.951480
(Iteration 51 / 200) loss: 1.778344
(Iteration 61 / 200) loss: 1.759060
(Iteration 71 / 200) loss: 1.865580
(Epoch 2 / 5) train acc: 0.391000; val_acc: 0.325000
(Iteration 81 / 200) loss: 1.997256
(Iteration 91 / 200) loss: 1.675952
(Iteration 101 / 200) loss: 1.539517
(Iteration 111 / 200) loss: 1.437328
(Epoch 3 / 5) train acc: 0.473000; val_acc: 0.340000
(Iteration 121 / 200) loss: 1.660326
(Iteration 131 / 200) loss: 1.495063
(Iteration 141 / 200) loss: 1.632314
(Iteration 151 / 200) loss: 1.686809
(Epoch 4 / 5) train acc: 0.495000; val_acc: 0.337000
(Iteration 161 / 200) loss: 1.495090
(Iteration 171 / 200) loss: 1.432555
(Iteration 181 / 200) loss: 1.352575
(Iteration 191 / 200) loss: 1.314671
(Epoch 5 / 5) train acc: 0.538000; val_acc: 0.359000
C:\Users\abbottjc\Anaconda3\envs\cs231n\lib\site-packages\matplotlib\cbook\deprecation.py:107: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.
warnings.warn(message, mplDeprecation, stacklevel=1)
RMSProp and Adam
RMSProp [1] and Adam [2] are update rules that set per-parameter learning rates by using a running average of the second moments of gradients.
In the file cs231n/optim.py, implement the RMSProp update rule in the rmsprop function and implement the Adam update rule in the adam function, and check your implementations using the tests below.
NOTE: Please implement the complete Adam update rule (with the bias correction mechanism), not the first simplified version mentioned in the course notes.
[1] Tijmen Tieleman and Geoffrey Hinton. “Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude.” COURSERA: Neural Networks for Machine Learning 4 (2012).
[2] Diederik Kingma and Jimmy Ba, “Adam: A Method for Stochastic Optimization”, ICLR 2015.
# Test RMSProp implementation
from cs231n.optim import rmsprop
N, D = 4, 5
w = np.linspace(-0.4, 0.6, num=N*D).reshape(N, D)
dw = np.linspace(-0.6, 0.4, num=N*D).reshape(N, D)
cache = np.linspace(0.6, 0.9, num=N*D).reshape(N, D)
config = {'learning_rate': 1e-2, 'cache': cache}
next_w, _ = rmsprop(w, dw, config=config)
expected_next_w = np.asarray([
[-0.39223849, -0.34037513, -0.28849239, -0.23659121, -0.18467247],
[-0.132737, -0.08078555, -0.02881884, 0.02316247, 0.07515774],
[ 0.12716641, 0.17918792, 0.23122175, 0.28326742, 0.33532447],
[ 0.38739248, 0.43947102, 0.49155973, 0.54365823, 0.59576619]])
expected_cache = np.asarray([
[ 0.5976, 0.6126277, 0.6277108, 0.64284931, 0.65804321],
[ 0.67329252, 0.68859723, 0.70395734, 0.71937285, 0.73484377],
[ 0.75037008, 0.7659518, 0.78158892, 0.79728144, 0.81302936],
[ 0.82883269, 0.84469141, 0.86060554, 0.87657507, 0.8926 ]])
# You should see relative errors around e-7 or less
print('next_w error: ', rel_error(expected_next_w, next_w))
print('cache error: ', rel_error(expected_cache, config['cache']))
next_w error: 9.524687511038133e-08
cache error: 2.6477955807156126e-09
# Test Adam implementation
from cs231n.optim import adam
N, D = 4, 5
w = np.linspace(-0.4, 0.6, num=N*D).reshape(N, D)
dw = np.linspace(-0.6, 0.4, num=N*D).reshape(N, D)
m = np.linspace(0.6, 0.9, num=N*D).reshape(N, D)
v = np.linspace(0.7, 0.5, num=N*D).reshape(N, D)
config = {'learning_rate': 1e-2, 'm': m, 'v': v, 't': 5}
next_w, _ = adam(w, dw, config=config)
expected_next_w = np.asarray([
[-0.40094747, -0.34836187, -0.29577703, -0.24319299, -0.19060977],
[-0.1380274, -0.08544591, -0.03286534, 0.01971428, 0.0722929],
[ 0.1248705, 0.17744702, 0.23002243, 0.28259667, 0.33516969],
[ 0.38774145, 0.44031188, 0.49288093, 0.54544852, 0.59801459]])
expected_v = np.asarray([
[ 0.69966, 0.68908382, 0.67851319, 0.66794809, 0.65738853,],
[ 0.64683452, 0.63628604, 0.6257431, 0.61520571, 0.60467385,],
[ 0.59414753, 0.58362676, 0.57311152, 0.56260183, 0.55209767,],
[ 0.54159906, 0.53110598, 0.52061845, 0.51013645, 0.49966, ]])
expected_m = np.asarray([
[ 0.48, 0.49947368, 0.51894737, 0.53842105, 0.55789474],
[ 0.57736842, 0.59684211, 0.61631579, 0.63578947, 0.65526316],
[ 0.67473684, 0.69421053, 0.71368421, 0.73315789, 0.75263158],
[ 0.77210526, 0.79157895, 0.81105263, 0.83052632, 0.85 ]])
# You should see relative errors around e-7 or less
print('next_w error: ', rel_error(expected_next_w, next_w))
print('v error: ', rel_error(expected_v, config['v']))
print('m error: ', rel_error(expected_m, config['m']))
next_w error: 1.1395691798535431e-07
v error: 4.208314038113071e-09
m error: 4.214963193114416e-09
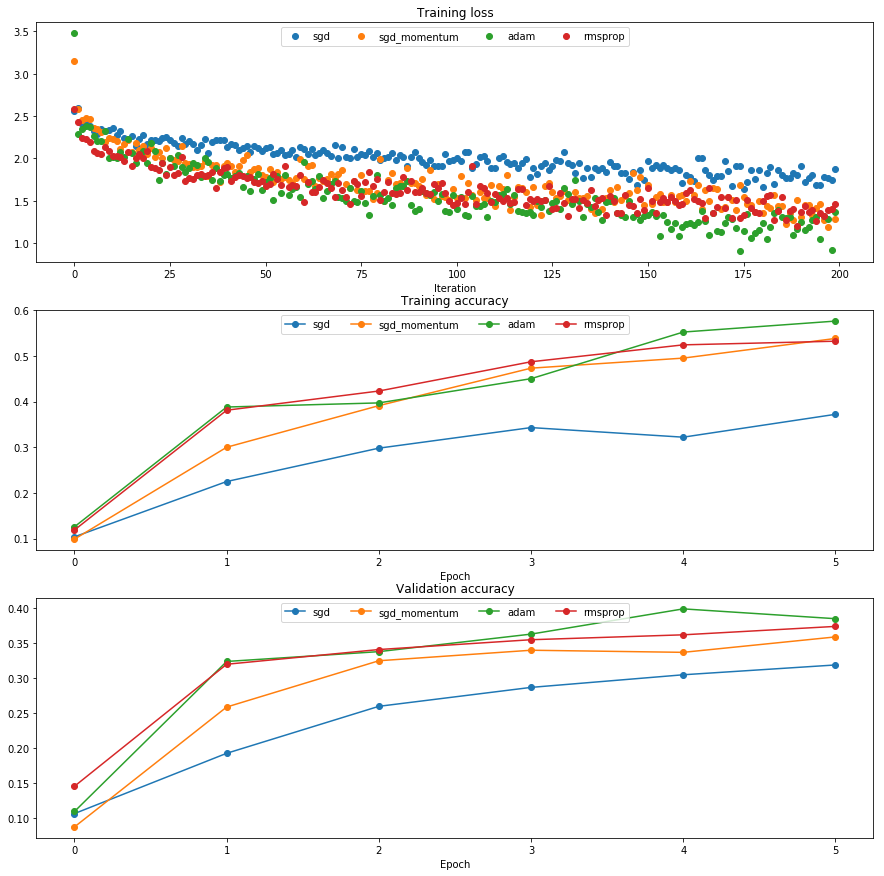
Once you have debugged your RMSProp and Adam implementations, run the following to train a pair of deep networks using these new update rules:
learning_rates = {'rmsprop': 1e-4, 'adam': 1e-3}
for update_rule in ['adam', 'rmsprop']:
print('running with ', update_rule)
model = FullyConnectedNet([100, 100, 100, 100, 100], weight_scale=5e-2)
solver = Solver(model, small_data,
num_epochs=5, batch_size=100,
update_rule=update_rule,
optim_config={
'learning_rate': learning_rates[update_rule]
},
verbose=True)
solvers[update_rule] = solver
solver.train()
print()
plt.subplot(3, 1, 1)
plt.title('Training loss')
plt.xlabel('Iteration')
plt.subplot(3, 1, 2)
plt.title('Training accuracy')
plt.xlabel('Epoch')
plt.subplot(3, 1, 3)
plt.title('Validation accuracy')
plt.xlabel('Epoch')
for update_rule, solver in list(solvers.items()):
plt.subplot(3, 1, 1)
plt.plot(solver.loss_history, 'o', label=update_rule)
plt.subplot(3, 1, 2)
plt.plot(solver.train_acc_history, '-o', label=update_rule)
plt.subplot(3, 1, 3)
plt.plot(solver.val_acc_history, '-o', label=update_rule)
for i in [1, 2, 3]:
plt.subplot(3, 1, i)
plt.legend(loc='upper center', ncol=4)
plt.gcf().set_size_inches(15, 15)
plt.show()
running with adam
(Iteration 1 / 200) loss: 3.476928
(Epoch 0 / 5) train acc: 0.126000; val_acc: 0.110000
C:\Users\abbottjc\Google Drive\School\UCD\Fall_2019\ELEC_5840_IndependentStudy\cs231_Stanford\spring1819_assignment2\cs231n\optim.py:163: RuntimeWarning: invalid value encountered in sqrt
next_w += -(config['learning_rate'] * config['mt']) / (np.sqrt(config['vt']) + config['epsilon'])
(Iteration 11 / 200) loss: 2.016536
(Iteration 21 / 200) loss: 2.182430
(Iteration 31 / 200) loss: 1.884025
(Epoch 1 / 5) train acc: 0.388000; val_acc: 0.324000
(Iteration 41 / 200) loss: 1.817217
(Iteration 51 / 200) loss: 1.721694
(Iteration 61 / 200) loss: 1.962812
(Iteration 71 / 200) loss: 1.537631
(Epoch 2 / 5) train acc: 0.397000; val_acc: 0.338000
(Iteration 81 / 200) loss: 1.569518
(Iteration 91 / 200) loss: 1.407079
(Iteration 101 / 200) loss: 1.399975
(Iteration 111 / 200) loss: 1.481901
(Epoch 3 / 5) train acc: 0.450000; val_acc: 0.363000
(Iteration 121 / 200) loss: 1.333740
(Iteration 131 / 200) loss: 1.464279
(Iteration 141 / 200) loss: 1.496734
(Iteration 151 / 200) loss: 1.338901
(Epoch 4 / 5) train acc: 0.552000; val_acc: 0.399000
(Iteration 161 / 200) loss: 1.227357
(Iteration 171 / 200) loss: 1.234783
(Iteration 181 / 200) loss: 1.233575
(Iteration 191 / 200) loss: 1.252079
(Epoch 5 / 5) train acc: 0.576000; val_acc: 0.385000
running with rmsprop
(Iteration 1 / 200) loss: 2.589166
(Epoch 0 / 5) train acc: 0.119000; val_acc: 0.146000
C:\Users\abbottjc\Google Drive\School\UCD\Fall_2019\ELEC_5840_IndependentStudy\cs231_Stanford\spring1819_assignment2\cs231n\optim.py:113: RuntimeWarning: invalid value encountered in sqrt
next_w += - config['learning_rate'] * dw / (np.sqrt(config['cache']) + config['epsilon'])
(Iteration 11 / 200) loss: 2.032921
(Iteration 21 / 200) loss: 1.897278
(Iteration 31 / 200) loss: 1.770793
(Epoch 1 / 5) train acc: 0.381000; val_acc: 0.320000
(Iteration 41 / 200) loss: 1.895732
(Iteration 51 / 200) loss: 1.681091
(Iteration 61 / 200) loss: 1.486923
(Iteration 71 / 200) loss: 1.628511
(Epoch 2 / 5) train acc: 0.423000; val_acc: 0.341000
(Iteration 81 / 200) loss: 1.506182
(Iteration 91 / 200) loss: 1.600674
(Iteration 101 / 200) loss: 1.478501
(Iteration 111 / 200) loss: 1.577709
(Epoch 3 / 5) train acc: 0.487000; val_acc: 0.355000
(Iteration 121 / 200) loss: 1.495931
(Iteration 131 / 200) loss: 1.525799
(Iteration 141 / 200) loss: 1.552580
(Iteration 151 / 200) loss: 1.654283
(Epoch 4 / 5) train acc: 0.524000; val_acc: 0.362000
(Iteration 161 / 200) loss: 1.589371
(Iteration 171 / 200) loss: 1.413529
(Iteration 181 / 200) loss: 1.500273
(Iteration 191 / 200) loss: 1.365943
(Epoch 5 / 5) train acc: 0.532000; val_acc: 0.374000
C:\Users\abbottjc\Anaconda3\envs\cs231n\lib\site-packages\matplotlib\cbook\deprecation.py:107: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.
warnings.warn(message, mplDeprecation, stacklevel=1)
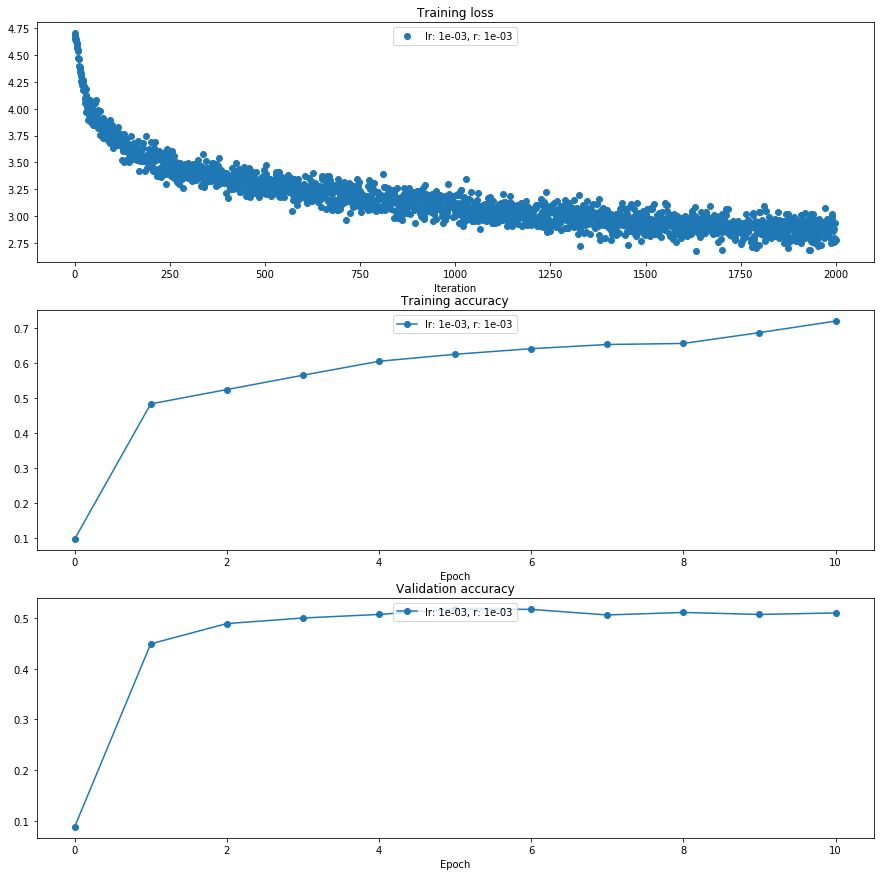
Train a good model!
Train the best fully-connected model that you can on CIFAR-10, storing your best model in the best_model variable. We require you to get at least 50% accuracy on the validation set using a fully-connected net.
If you are careful it should be possible to get accuracies above 55%, but we don’t require it for this part and won’t assign extra credit for doing so. Later in the assignment we will ask you to train the best convolutional network that you can on CIFAR-10, and we would prefer that you spend your effort working on convolutional nets rather than fully-connected nets.
You might find it useful to complete the BatchNormalization.ipynb and Dropout.ipynb notebooks before completing this part, since those techniques can help you train powerful models.
best_model = None
data = get_CIFAR10_data()
for k, v in list(data.items()):
print(('%s: ' % k, v.shape))
################################################################################
# TODO: Train the best FullyConnectedNet that you can on CIFAR-10. You might #
# find batch/layer normalization and dropout useful. Store your best model in #
# the best_model variable. #
################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
num_train = 40000
print('Training with %s images' % N)
small_data = {
'X_train': data['X_train'][:num_train],
'y_train': data['y_train'][:num_train],
'X_val': data['X_val'],
'y_val': data['y_val'],
}
best_val = -1
best_params = {}
best_solver = None
solvers = {}
learning_rates = {}
h = [150, 125, 100, 75, 50]
w = 5e-2
update_rule = 'adam'
for lr in [1e-2, 1e-3, 1e-4]:
for r in [1e-2, 1e-3, 1e-4]:
print('running with learning rate: ', lr)
print('running with weight_scale: ', w)
print('running with r: ', r)
print('running with h: ', str(h))
learning_rates[update_rule] = lr
model = FullyConnectedNet(h, weight_scale=w, normalization='batchnorm', reg=r)
solver = Solver(model, small_data,
num_epochs=10, batch_size=200,
update_rule=update_rule,
optim_config={
'learning_rate': learning_rates[update_rule]
},
verbose=True)
solver.train()
solvers[(lr, w, r, str(h))] = solver
print()
if np.max(solver.val_acc_history) > best_val:
best_solver = solver
best_val = np.max(solver.val_acc_history)
best_model = model
best_params['lr'] = lr
best_params['w'] = w
best_params['r'] = r
best_params['h'] = h
print("Validation History Max: %s" % np.max(best_solver.val_acc_history))
print("Best Hyper Parameters ---> lr: %.0e, r: %.0e" % (best_params['lr'], best_params['r']))
plt.subplot(3, 1, 1)
plt.title('Training loss')
plt.xlabel('Iteration')
plt.subplot(3, 1, 2)
plt.title('Training accuracy')
plt.xlabel('Epoch')
plt.subplot(3, 1, 3)
plt.title('Validation accuracy')
plt.xlabel('Epoch')
for k in solvers.keys():
l = "lr: %.0e, r: %.0e" % (k[0], k[2])
plt.subplot(3, 1, 1)
plt.plot(solvers[k].loss_history, 'o', label=l)
plt.subplot(3, 1, 2)
plt.plot(solvers[k].train_acc_history, '-o', label=l)
plt.subplot(3, 1, 3)
plt.plot(solvers[k].val_acc_history, '-o', label=l)
for i in [1, 2, 3]:
plt.subplot(3, 1, i)
plt.legend(loc='upper center', ncol=4)
plt.gcf().set_size_inches(15, 15)
plt.show()
best_model = model
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
################################################################################
# END OF YOUR CODE #
################################################################################
('X_train: ', (49000, 3, 32, 32))
('y_train: ', (49000,))
('X_val: ', (1000, 3, 32, 32))
('y_val: ', (1000,))
('X_test: ', (1000, 3, 32, 32))
('y_test: ', (1000,))
Training with 40000 images
running with learning rate: 0.001
running with weight_scale: 0.05
running with r: 0.001
running with h: [150, 125, 100, 75, 50]
(Iteration 1 / 2000) loss: 4.702821
(Epoch 0 / 10) train acc: 0.097000; val_acc: 0.088000
(Iteration 11 / 2000) loss: 4.473736
(Iteration 21 / 2000) loss: 4.241587
(Iteration 31 / 2000) loss: 4.182647
(Iteration 41 / 2000) loss: 4.082689
(Iteration 51 / 2000) loss: 3.948599
(Iteration 61 / 2000) loss: 3.874086
(Iteration 71 / 2000) loss: 3.881175
(Iteration 81 / 2000) loss: 3.839554
(Iteration 91 / 2000) loss: 3.749097
(Iteration 101 / 2000) loss: 3.797978
(Iteration 111 / 2000) loss: 3.667052
(Iteration 121 / 2000) loss: 3.678544
(Iteration 131 / 2000) loss: 3.763255
(Iteration 141 / 2000) loss: 3.513491
(Iteration 151 / 2000) loss: 3.592632
(Iteration 161 / 2000) loss: 3.567524
(Iteration 171 / 2000) loss: 3.419507
(Iteration 181 / 2000) loss: 3.681849
(Iteration 191 / 2000) loss: 3.444785
(Epoch 1 / 10) train acc: 0.484000; val_acc: 0.449000
(Iteration 201 / 2000) loss: 3.572305
(Iteration 211 / 2000) loss: 3.686476
(Iteration 221 / 2000) loss: 3.376790
(Iteration 231 / 2000) loss: 3.428059
(Iteration 241 / 2000) loss: 3.419342
(Iteration 251 / 2000) loss: 3.514121
(Iteration 261 / 2000) loss: 3.359176
(Iteration 271 / 2000) loss: 3.317012
(Iteration 281 / 2000) loss: 3.404257
(Iteration 291 / 2000) loss: 3.466597
(Iteration 301 / 2000) loss: 3.381736
(Iteration 311 / 2000) loss: 3.405248
(Iteration 321 / 2000) loss: 3.429050
(Iteration 331 / 2000) loss: 3.449639
(Iteration 341 / 2000) loss: 3.321329
(Iteration 351 / 2000) loss: 3.397644
(Iteration 361 / 2000) loss: 3.452207
(Iteration 371 / 2000) loss: 3.357880
(Iteration 381 / 2000) loss: 3.425040
(Iteration 391 / 2000) loss: 3.314486
(Epoch 2 / 10) train acc: 0.525000; val_acc: 0.489000
(Iteration 401 / 2000) loss: 3.381399
(Iteration 411 / 2000) loss: 3.321884
(Iteration 421 / 2000) loss: 3.350730
(Iteration 431 / 2000) loss: 3.342693
(Iteration 441 / 2000) loss: 3.291284
(Iteration 451 / 2000) loss: 3.238704
(Iteration 461 / 2000) loss: 3.227358
(Iteration 471 / 2000) loss: 3.215234
(Iteration 481 / 2000) loss: 3.251301
(Iteration 491 / 2000) loss: 3.240412
(Iteration 501 / 2000) loss: 3.250454
(Iteration 511 / 2000) loss: 3.315653
(Iteration 521 / 2000) loss: 3.318210
(Iteration 531 / 2000) loss: 3.385151
(Iteration 541 / 2000) loss: 3.203787
(Iteration 551 / 2000) loss: 3.262581
(Iteration 561 / 2000) loss: 3.251019
(Iteration 571 / 2000) loss: 3.051607
(Iteration 581 / 2000) loss: 3.242018
(Iteration 591 / 2000) loss: 3.161122
(Epoch 3 / 10) train acc: 0.566000; val_acc: 0.500000
(Iteration 601 / 2000) loss: 3.263389
(Iteration 611 / 2000) loss: 3.122368
(Iteration 621 / 2000) loss: 3.290376
(Iteration 631 / 2000) loss: 3.259276
(Iteration 641 / 2000) loss: 3.132517
(Iteration 651 / 2000) loss: 3.204078
(Iteration 661 / 2000) loss: 3.307073
(Iteration 671 / 2000) loss: 3.338288
(Iteration 681 / 2000) loss: 3.068155
(Iteration 691 / 2000) loss: 3.058427
(Iteration 701 / 2000) loss: 3.299976
(Iteration 711 / 2000) loss: 3.242403
(Iteration 721 / 2000) loss: 3.174736
(Iteration 731 / 2000) loss: 3.181030
(Iteration 741 / 2000) loss: 3.166734
(Iteration 751 / 2000) loss: 3.102395
(Iteration 761 / 2000) loss: 3.132619
(Iteration 771 / 2000) loss: 3.143259
(Iteration 781 / 2000) loss: 3.309349
(Iteration 791 / 2000) loss: 3.118866
(Epoch 4 / 10) train acc: 0.606000; val_acc: 0.507000
(Iteration 801 / 2000) loss: 3.159957
(Iteration 811 / 2000) loss: 3.099373
(Iteration 821 / 2000) loss: 3.188910
(Iteration 831 / 2000) loss: 3.069816
(Iteration 841 / 2000) loss: 3.213736
(Iteration 851 / 2000) loss: 2.984929
(Iteration 861 / 2000) loss: 2.967305
(Iteration 871 / 2000) loss: 3.052255
(Iteration 881 / 2000) loss: 3.109186
(Iteration 891 / 2000) loss: 3.221044
(Iteration 901 / 2000) loss: 3.069780
(Iteration 911 / 2000) loss: 3.075569
(Iteration 921 / 2000) loss: 3.285626
(Iteration 931 / 2000) loss: 3.089235
(Iteration 941 / 2000) loss: 3.207897
(Iteration 951 / 2000) loss: 3.232408
(Iteration 961 / 2000) loss: 3.196016
(Iteration 971 / 2000) loss: 3.075931
(Iteration 981 / 2000) loss: 3.168164
(Iteration 991 / 2000) loss: 3.095656
(Epoch 5 / 10) train acc: 0.626000; val_acc: 0.518000
(Iteration 1001 / 2000) loss: 3.051236
(Iteration 1011 / 2000) loss: 3.193495
(Iteration 1021 / 2000) loss: 2.911715
(Iteration 1031 / 2000) loss: 3.085810
(Iteration 1041 / 2000) loss: 3.055297
(Iteration 1051 / 2000) loss: 3.013372
(Iteration 1061 / 2000) loss: 3.212839
(Iteration 1071 / 2000) loss: 2.989970
(Iteration 1081 / 2000) loss: 3.059366
(Iteration 1091 / 2000) loss: 3.111931
(Iteration 1101 / 2000) loss: 3.138709
(Iteration 1111 / 2000) loss: 3.069310
(Iteration 1121 / 2000) loss: 3.109569
(Iteration 1131 / 2000) loss: 3.018170
(Iteration 1141 / 2000) loss: 3.082343
(Iteration 1151 / 2000) loss: 2.911705
(Iteration 1161 / 2000) loss: 3.074176
(Iteration 1171 / 2000) loss: 3.019455
(Iteration 1181 / 2000) loss: 3.054467
(Iteration 1191 / 2000) loss: 2.945914
(Epoch 6 / 10) train acc: 0.642000; val_acc: 0.517000
(Iteration 1201 / 2000) loss: 2.928700
(Iteration 1211 / 2000) loss: 2.987245
(Iteration 1221 / 2000) loss: 2.978378
(Iteration 1231 / 2000) loss: 2.897479
(Iteration 1241 / 2000) loss: 2.851011
(Iteration 1251 / 2000) loss: 2.931286
(Iteration 1261 / 2000) loss: 3.027464
(Iteration 1271 / 2000) loss: 2.932876
(Iteration 1281 / 2000) loss: 2.984848
(Iteration 1291 / 2000) loss: 2.960122
(Iteration 1301 / 2000) loss: 3.098356
(Iteration 1311 / 2000) loss: 3.072850
(Iteration 1321 / 2000) loss: 2.977965
(Iteration 1331 / 2000) loss: 2.933218
(Iteration 1341 / 2000) loss: 2.944676
(Iteration 1351 / 2000) loss: 2.923758
(Iteration 1361 / 2000) loss: 3.002594
(Iteration 1371 / 2000) loss: 2.984902
(Iteration 1381 / 2000) loss: 2.920594
(Iteration 1391 / 2000) loss: 2.934059
(Epoch 7 / 10) train acc: 0.654000; val_acc: 0.506000
(Iteration 1401 / 2000) loss: 3.023083
(Iteration 1411 / 2000) loss: 2.869718
(Iteration 1421 / 2000) loss: 2.852887
(Iteration 1431 / 2000) loss: 2.992467
(Iteration 1441 / 2000) loss: 2.955031
(Iteration 1451 / 2000) loss: 3.018915
(Iteration 1461 / 2000) loss: 2.861268
(Iteration 1471 / 2000) loss: 3.064988
(Iteration 1481 / 2000) loss: 2.875540
(Iteration 1491 / 2000) loss: 2.984122
(Iteration 1501 / 2000) loss: 3.022115
(Iteration 1511 / 2000) loss: 2.932119
(Iteration 1521 / 2000) loss: 2.849853
(Iteration 1531 / 2000) loss: 2.950841
(Iteration 1541 / 2000) loss: 2.804516
(Iteration 1551 / 2000) loss: 3.119244
(Iteration 1561 / 2000) loss: 2.920354
(Iteration 1571 / 2000) loss: 2.929937
(Iteration 1581 / 2000) loss: 2.984245
(Iteration 1591 / 2000) loss: 2.953212
(Epoch 8 / 10) train acc: 0.657000; val_acc: 0.511000
(Iteration 1601 / 2000) loss: 2.981349
(Iteration 1611 / 2000) loss: 2.942551
(Iteration 1621 / 2000) loss: 2.888227
(Iteration 1631 / 2000) loss: 2.902267
(Iteration 1641 / 2000) loss: 2.881044
(Iteration 1651 / 2000) loss: 2.953636
(Iteration 1661 / 2000) loss: 2.887922
(Iteration 1671 / 2000) loss: 2.888567
(Iteration 1681 / 2000) loss: 3.001323
(Iteration 1691 / 2000) loss: 2.874911
(Iteration 1701 / 2000) loss: 2.855220
(Iteration 1711 / 2000) loss: 2.898995
(Iteration 1721 / 2000) loss: 2.903845
(Iteration 1731 / 2000) loss: 2.873008
(Iteration 1741 / 2000) loss: 2.947614
(Iteration 1751 / 2000) loss: 2.741861
(Iteration 1761 / 2000) loss: 2.860919
(Iteration 1771 / 2000) loss: 2.855171
(Iteration 1781 / 2000) loss: 2.928669
(Iteration 1791 / 2000) loss: 2.928403
(Epoch 9 / 10) train acc: 0.688000; val_acc: 0.507000
(Iteration 1801 / 2000) loss: 3.033933
(Iteration 1811 / 2000) loss: 2.831665
(Iteration 1821 / 2000) loss: 2.876718
(Iteration 1831 / 2000) loss: 2.810841
(Iteration 1841 / 2000) loss: 2.890386
(Iteration 1851 / 2000) loss: 2.967236
(Iteration 1861 / 2000) loss: 2.895218
(Iteration 1871 / 2000) loss: 3.018997
(Iteration 1881 / 2000) loss: 2.973243
(Iteration 1891 / 2000) loss: 2.988265
(Iteration 1901 / 2000) loss: 2.780205
(Iteration 1911 / 2000) loss: 2.795321
(Iteration 1921 / 2000) loss: 2.795344
(Iteration 1931 / 2000) loss: 2.681454
(Iteration 1941 / 2000) loss: 3.023325
(Iteration 1951 / 2000) loss: 2.775680
(Iteration 1961 / 2000) loss: 2.868830
(Iteration 1971 / 2000) loss: 2.825721
(Iteration 1981 / 2000) loss: 2.844892
(Iteration 1991 / 2000) loss: 3.020823
(Epoch 10 / 10) train acc: 0.721000; val_acc: 0.510000
Validation History Max: 0.518
Best Hyper Parameters ---> lr: 1e-03, r: 1e-03
C:\Users\abbottjc\Anaconda3\envs\cs231n\lib\site-packages\matplotlib\cbook\deprecation.py:107: MatplotlibDeprecationWarning: Adding an axes using the same arguments as a previous axes currently reuses the earlier instance. In a future version, a new instance will always be created and returned. Meanwhile, this warning can be suppressed, and the future behavior ensured, by passing a unique label to each axes instance.
warnings.warn(message, mplDeprecation, stacklevel=1)
Test your model!
Run your best model on the validation and test sets. You should achieve above 50% accuracy on the validation set.
y_test_pred = np.argmax(best_model.loss(data['X_test']), axis=1)
y_val_pred = np.argmax(best_model.loss(data['X_val']), axis=1)
print('Validation set accuracy: ', (y_val_pred == data['y_val']).mean())
print('Test set accuracy: ', (y_test_pred == data['y_test']).mean())
Validation set accuracy: 0.514
Test set accuracy: 0.526